用python快速过滤html指定标签函数 用python快速过滤html指定标签函数"""@author: MR.N@created: 2022/3/30 Wed.@version: 1.0""" import ioimport re def filter_html_tags(text): htmltags = ['div', 'ul', 'li', 'ol', 'p', 'span', 'form', ' PYTHON编程 2023年08月15日 0 点赞 0 评论 528 浏览
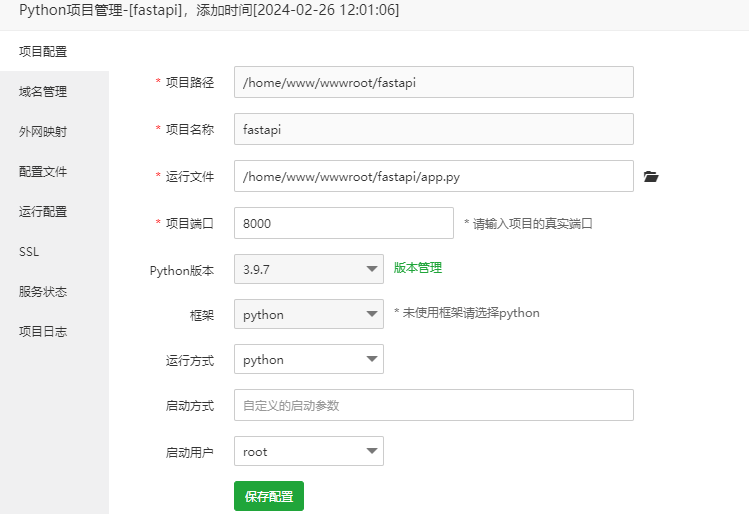
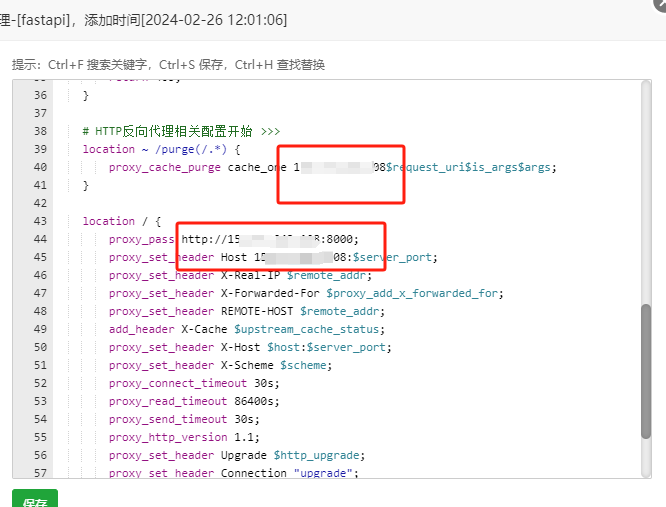
FastAPI在宝塔面板中的部署外网域名 在宝塔中在部署fastapi时常出现的几个简单问题总结:1.在服务上部署成功但是外网ip+端口访问不了,是因为绑定的127.0.0.1内网 未像外网开放,要做端口映射 或者运行程序时直接设置绑定成外网ip在部署fastapi时的简单fastapi示例:from fastapi import FastAPIimport asyncioimport nest_asyncionest_asyn PYTHON编程 2024年02月26日 0 点赞 0 评论 464 浏览
python 写一个函数 输入文本 过滤去除文本中的手机号码 座机号码 python 写一个函数 输入文本 过滤去除文本中的手机号码 座机号码以及 03-3239-061或03-3239061 0120-380-688类似的号码以下是用正则表达式实现的代码:def filter_phone(text): # 匹配日本手机号码格式 pattern_phone = r'\d{2,4}-\d{2,4}-\d{4}' # 匹配日本座机号 PYTHON编程 2023年06月06日 0 点赞 0 评论 461 浏览
wordpress文章发布出现 Fault -32700: 'parse error. not well formed错误处理方法 PYTHON编程 2023年07月15日 0 点赞 0 评论 461 浏览
python提取字符串中的手机号 python 写一个函数 用来过滤手机号码 座机号码以及 03-3239-061或03-3239061 0120-380-688类似的号码清除请问需要过滤掉什么样的手机号码和座机号码?比如区号、长度、特定开头等限制吗?以下是 Python 的代码实现:```pythonimport redef filter_phone_number(number): # 过滤手机号码 PYTHON编程 2023年06月06日 0 点赞 0 评论 459 浏览
django ORM 多对多的主机管理 django ORM 多对多的主机管理 主要是对ORM 不是太好理解。后端一点都不是很难写,就是前段 的ajax 和JQ 很烦人,上班的时候写的发毛 进入主题吧=。- 表的结构如下:from django.db import models# Create your models here.class Host(models.Mod PYTHON编程 2023年06月20日 0 点赞 0 评论 413 浏览
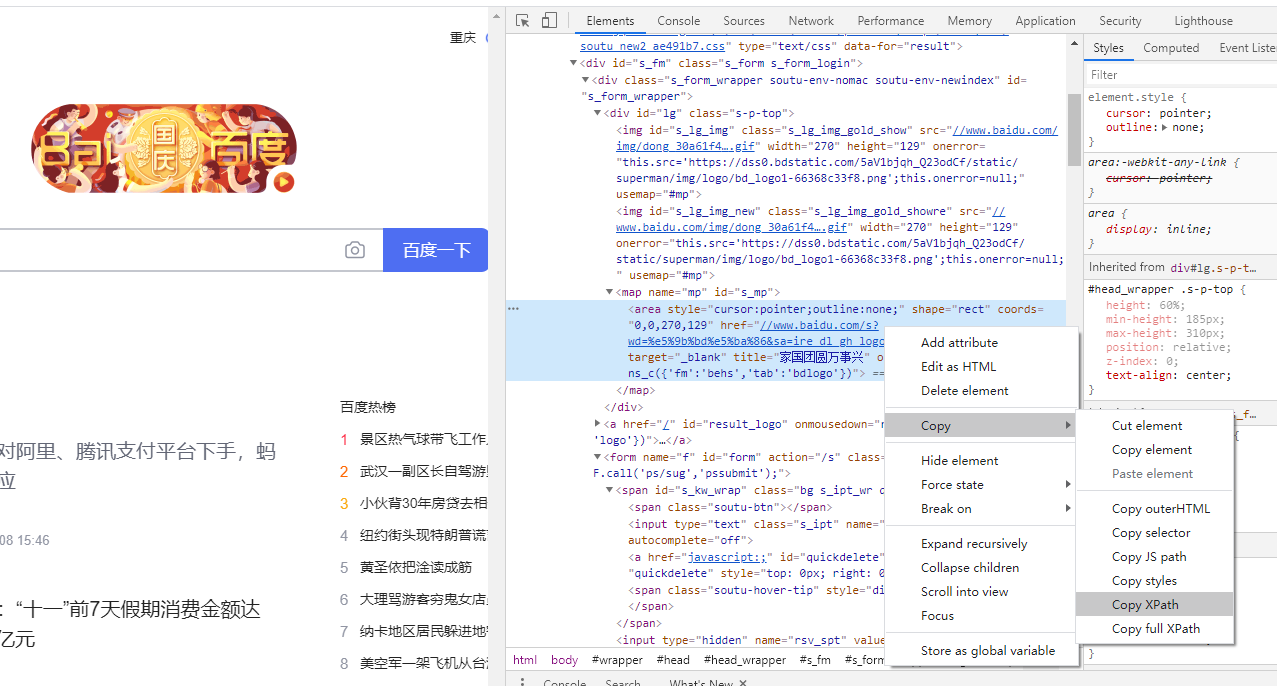
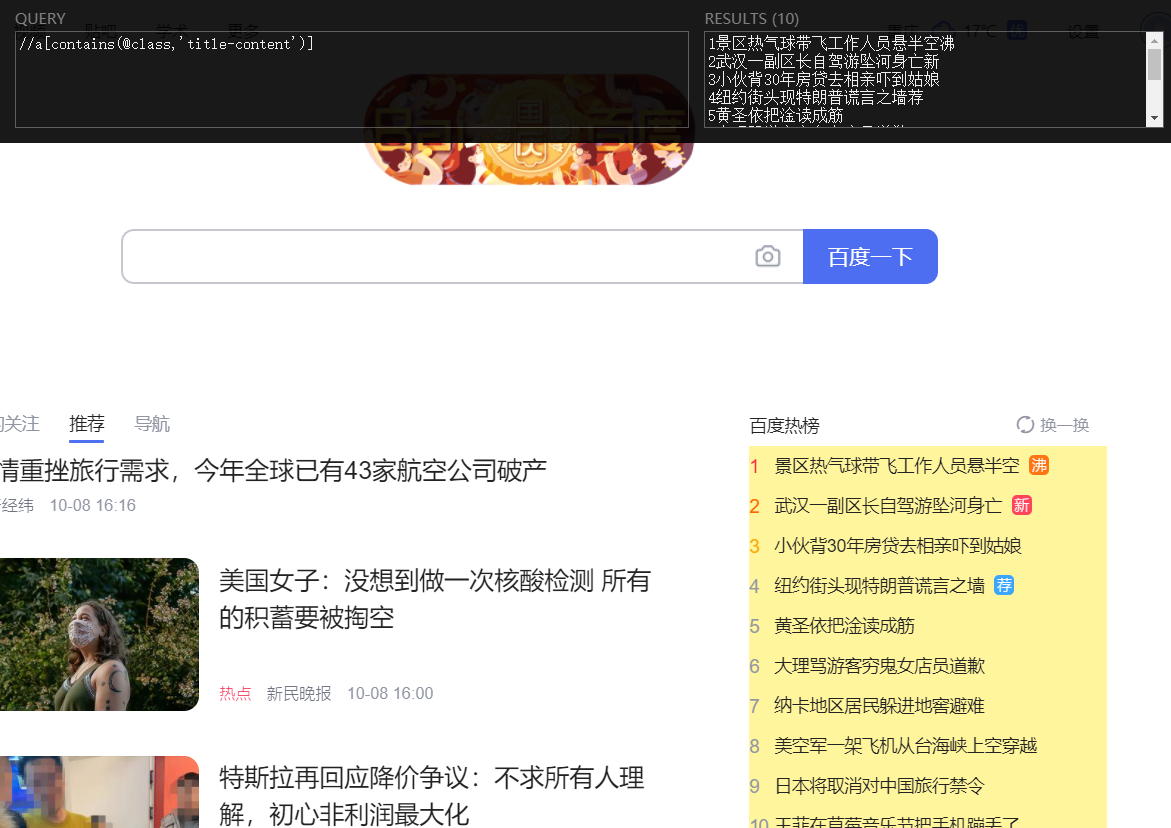
使用 Scrapy 的 xpath() 方法提取以 "/" 开头或以特定网址开头的链接方法 要使用 Scrapy 的 response.xpath() 方法提取指定 XPath 表达式匹配到的所有内链(即 <a> 标签中的链接),您可以使用以下方法如果您想要提取以 "/" 开头或以特定网址开头的链接,可以使用适当的 XPath 表达式和条件来实现。以下是一个示例:def parse(self, response): # 提取所有包含 class="content-w PYTHON编程 2024年03月08日 0 点赞 0 评论 383 浏览
python使用xpath用法教程(超详细) 使用时先安装 lxml 包开始使用#和beautifulsoup类似,首先我们需要得到一个文档树把文本转换成一个文档树对象from lxml import etree if __name__ == '__main__': doc=''' <div> <ul> <li class="item-0"><a href="link1.html">f PYTHON编程 2023年04月10日 0 点赞 0 评论 380 浏览