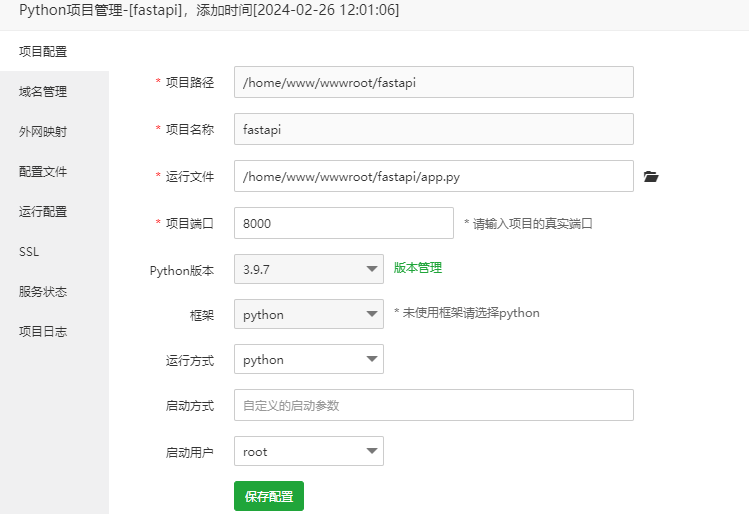
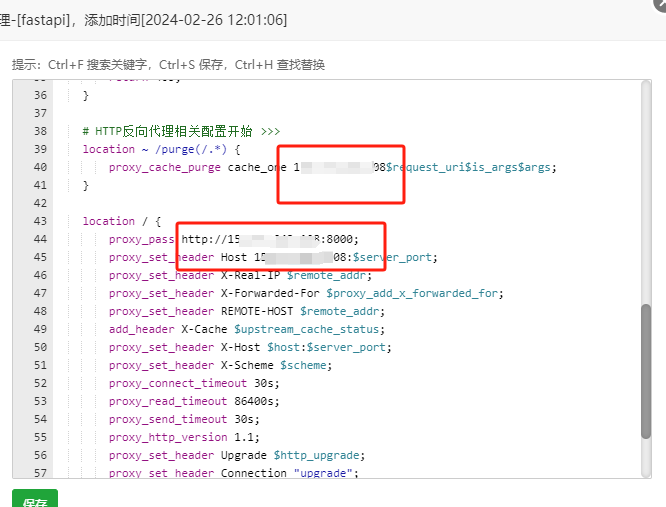
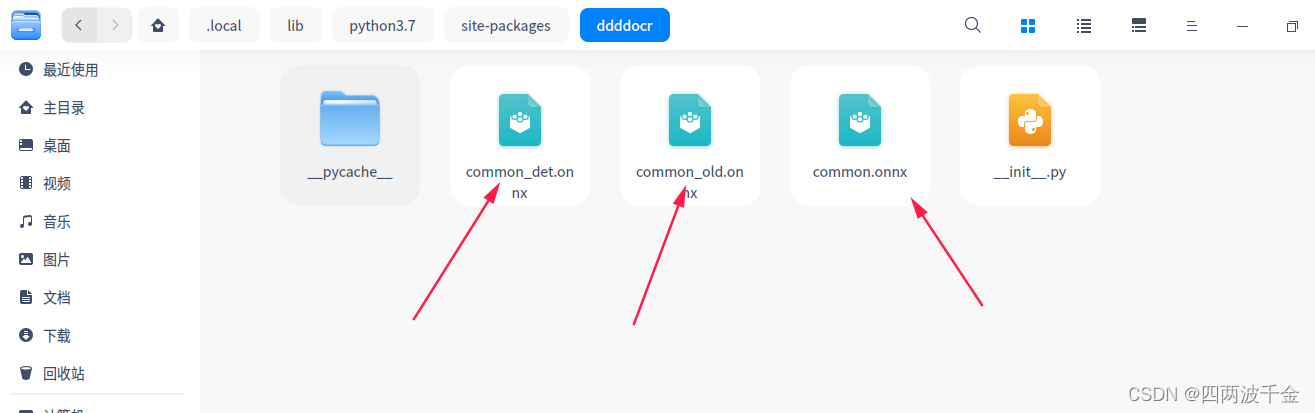
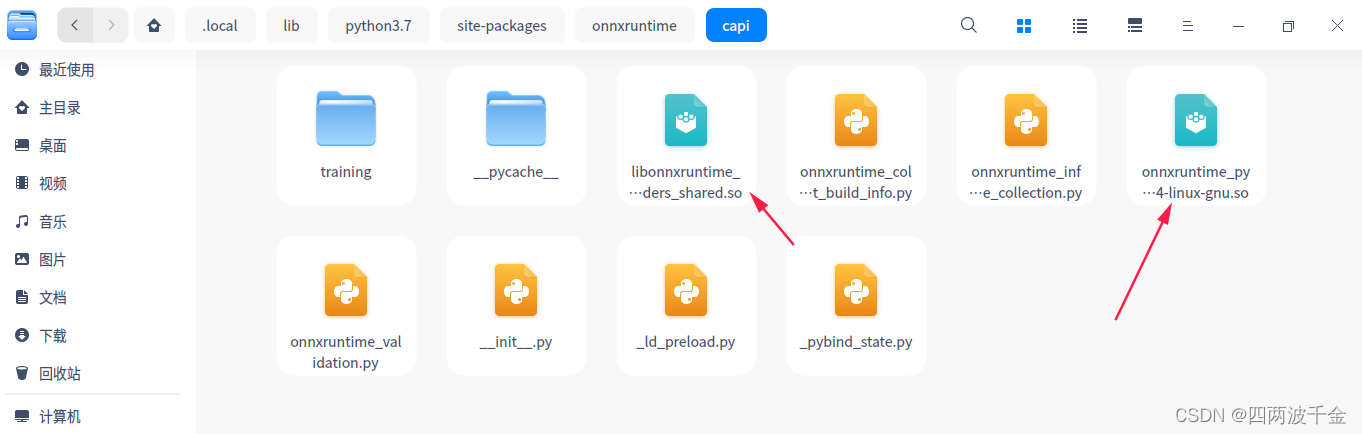
使用 Scrapy 的 xpath() 方法提取以 "/" 开头或以特定网址开头的链接方法
要使用 Scrapy 的 response.xpath() 方法提取指定 XPath 表达式匹配到的所有内链(即 <a> 标签中的链接),您可以使用以下方法如果您想要提取以 "/" 开头或以特定网址开头的链接,可以使用适当的 XPath 表达式和条件来实现。以下是一个示例:def parse(self, response): # 提取所有包含 class="content-w