PYTHON编程
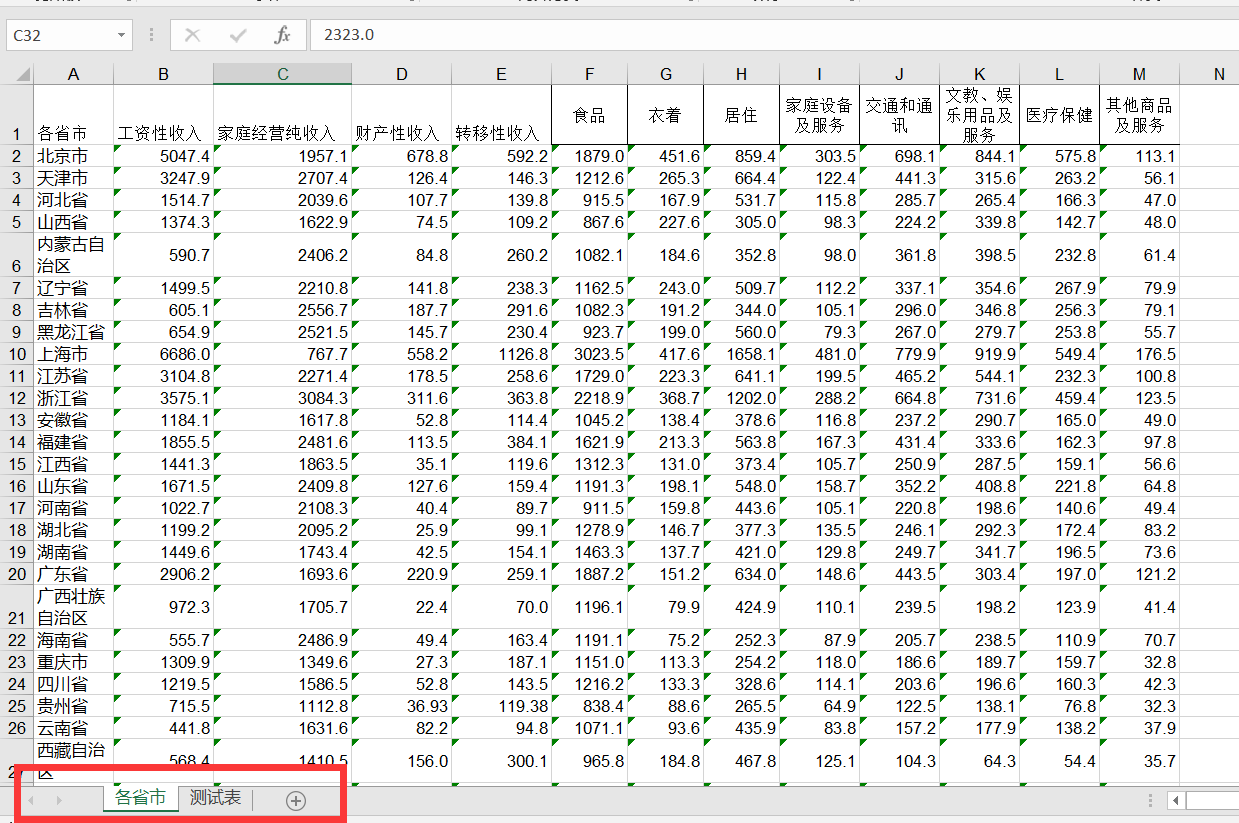

Python使用xmlrpc操作WordPress:发布文章、新建标签和分类目录等
一、安装依赖Python 调用 WordPress xmlrpc 需要的模块是 python_wordpress_xmlrpc,直接通过 pip 安装即可(老王这里用的是 python3):pip3 install python_wordpress_xmlrpc之后结合 Python 代码可以实现 WordPress 自动发布文章的功能。二、源码分享1、发布文章其中 post_status 可以是
python遍历文件夹下所有文件
话不多说,上代码:遍历文件内的所有文件(包括子目录内的文件)import osfile = r'D:\dataset\makelabels\demo'for root, dirs, files in os.walk(file): for file in files: path = os.path.join(root,

python的COUNT()函数用法是什么
count()函数描述:统计字符串里某个字符出现的次数。可以选择字符串索引的起始位置和结束位置。语法:str.count("char", start,end) 或 str.count("char") -> int 返回整数str —— 为要统计的字符(可以是单字符,也可以是多字符)。star —— 为索引字符串的起始位置,默认参数为0。end —— 为索引字符串的结束位置,默认参数为字符串长
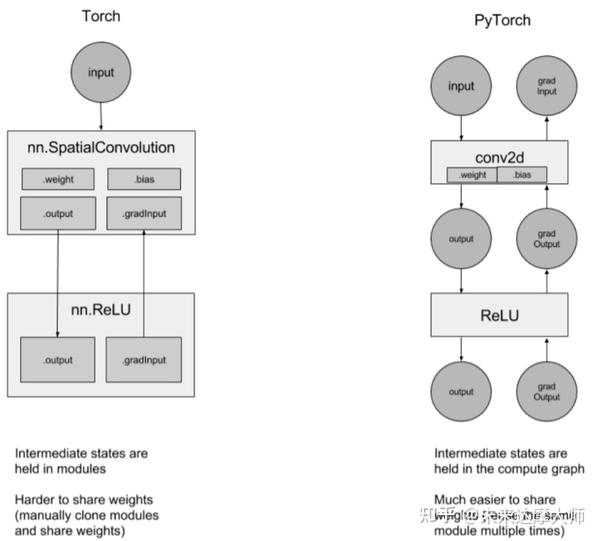
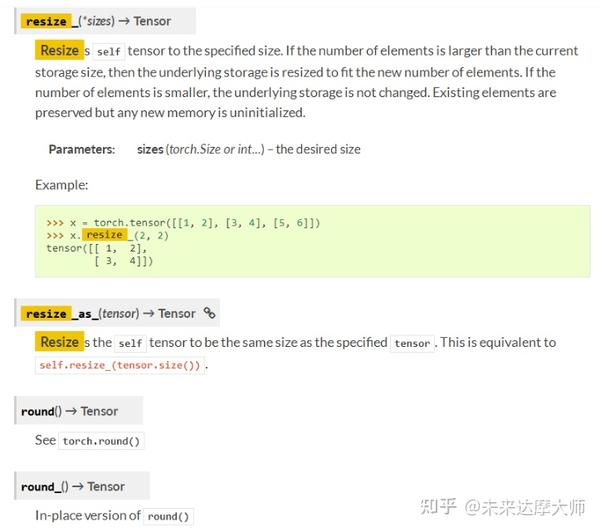
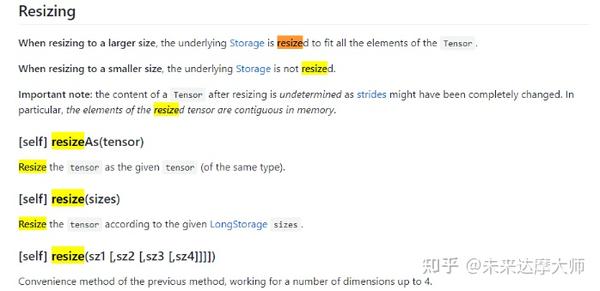
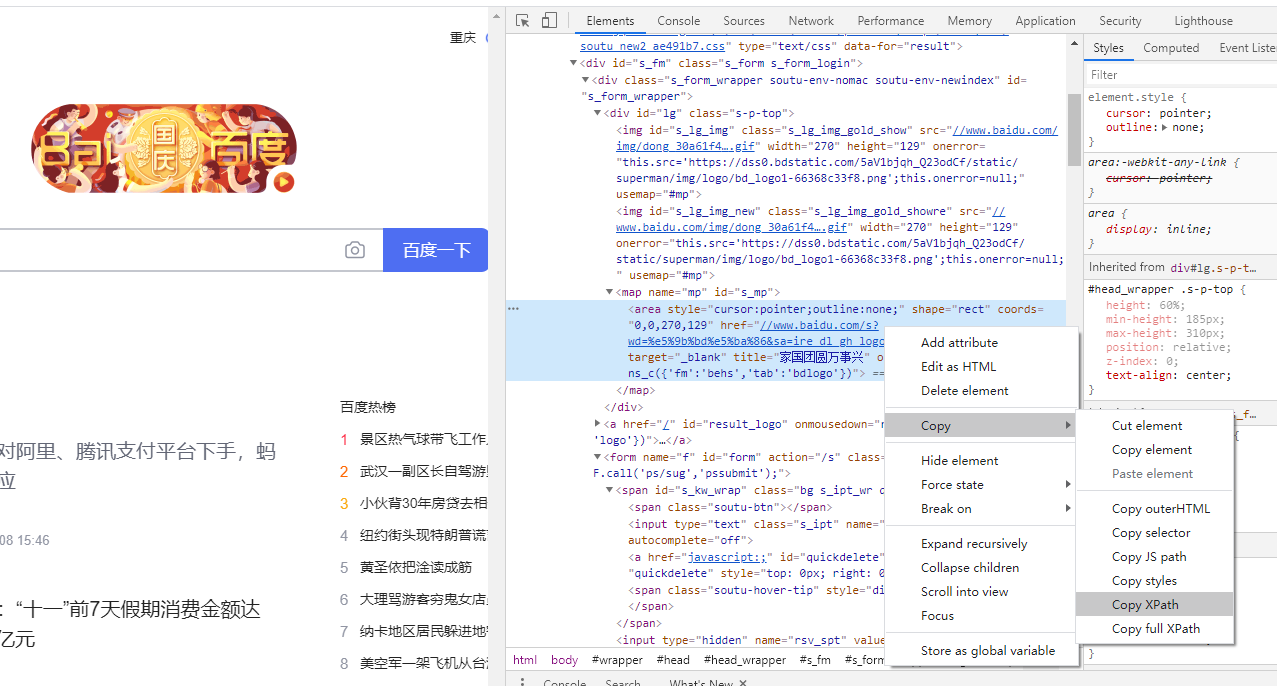
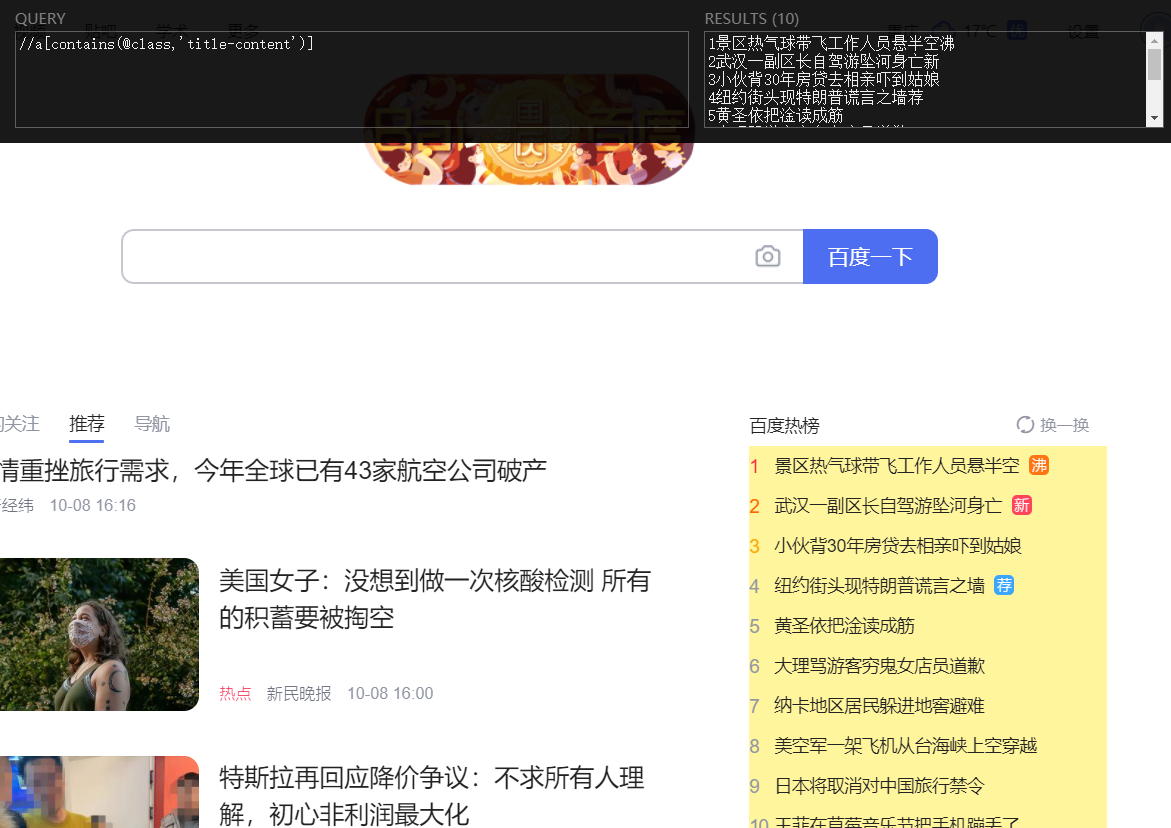
使用 Scrapy 的 xpath() 方法提取以 "/" 开头或以特定网址开头的链接方法
要使用 Scrapy 的 response.xpath() 方法提取指定 XPath 表达式匹配到的所有内链(即 <a> 标签中的链接),您可以使用以下方法如果您想要提取以 "/" 开头或以特定网址开头的链接,可以使用适当的 XPath 表达式和条件来实现。以下是一个示例:def parse(self, response): # 提取所有包含 class="content-w

python 写一个函数 输入文本 过滤去除文本中的手机号码 座机号码
python 写一个函数 输入文本 过滤去除文本中的手机号码 座机号码以及 03-3239-061或03-3239061 0120-380-688类似的号码以下是用正则表达式实现的代码:def filter_phone(text): # 匹配日本手机号码格式 pattern_phone = r'\d{2,4}-\d{2,4}-\d{4}' # 匹配日本座机号
